LlaMa-2-7B&LlaMa-2-7B-chat
模型介绍
LlaMa 2
LlaMa 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. This is the repository for the 7B pretrained model. Links to other models can be found in the index at the bottom.
启动方式
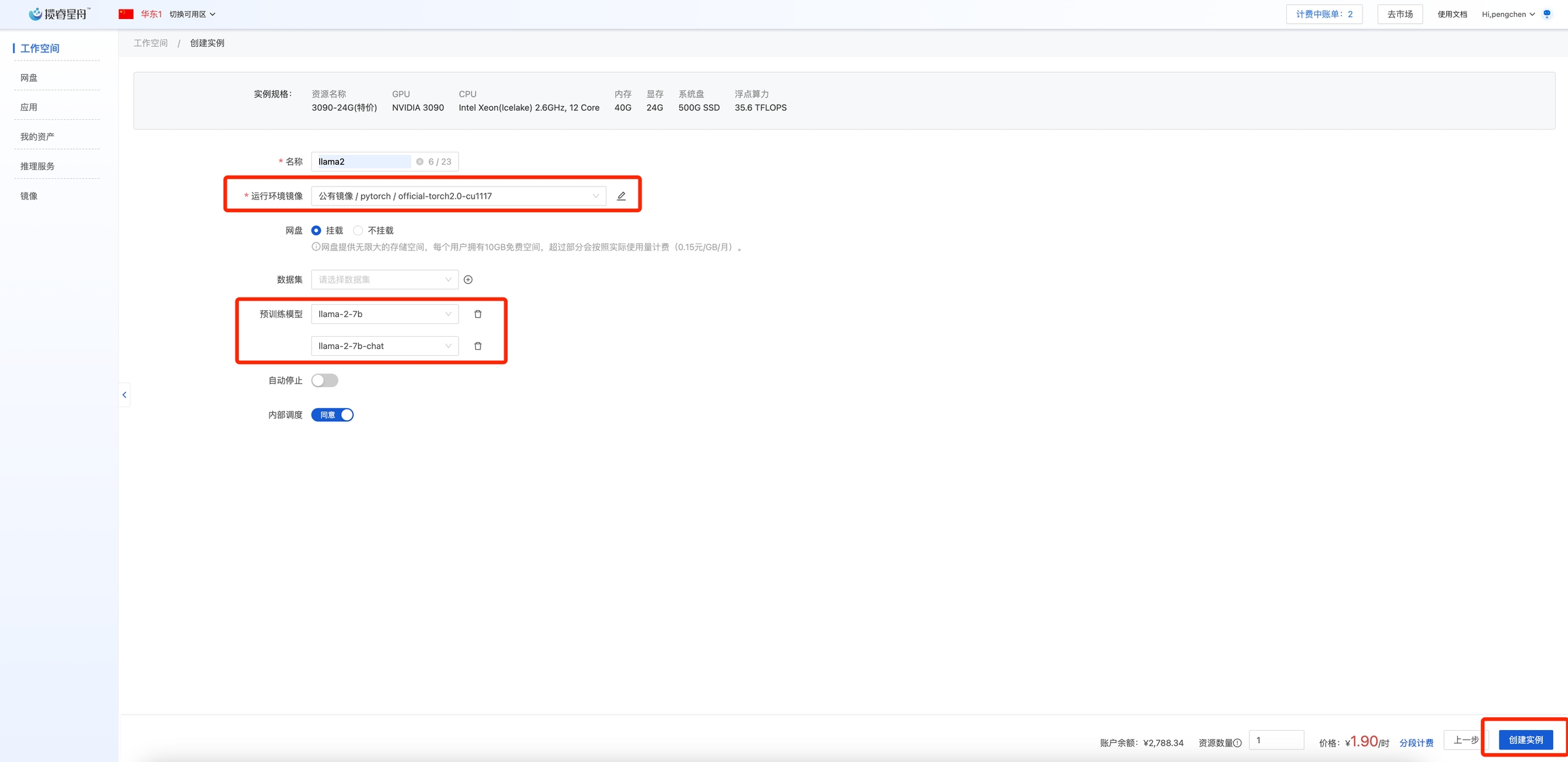
创建工作空间,按需选择GPU资源
挂载公有镜像pytorch: official-torch2.0-cu1117。选择预训练模型: llama-2-7b和llama-2-7b-chat
创建工作空间
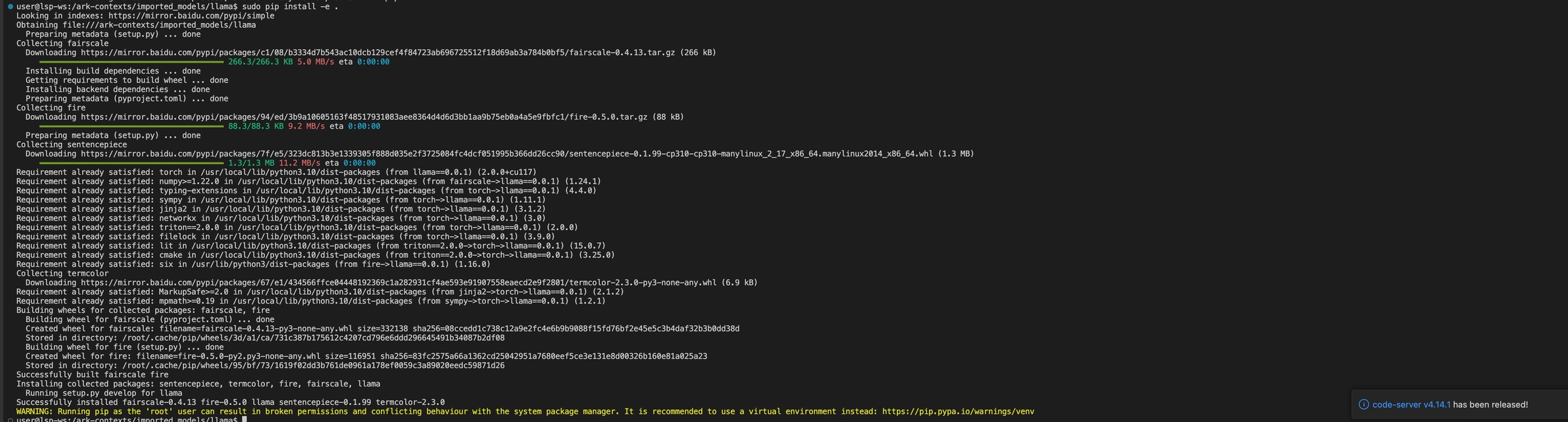
创建完成后,打开vscode或jupyter,在终端中输入以下命令,可能需要学术网站加速
使用模型
LlaMa-2-7b
LlaMa-2-7b-chat
Last updated